シフトレジスタ(74HC595)の使い方という以前の記事において、汎用IOポートをソフトウエアで制御してシフトレジスタ(74HC595)を操作するというのは実験しました。
ですが、この方法ではプログラムサイズも大きくなり、動作速度も遅くなってしまうという問題があります。
そこで、今回はAVRに搭載されている周辺機能であるSPIを使い、ハードウエアでシリアルデータとクロックを送出するようにしてみたいと思います。
どれぐらいのコードサイズの削減、動作速度の向上が出来るかを実験してみます。
ソフトウエアの場合(関数呼び出し等のオーバーヘッドは考慮しない)
データセット クロックHi クロックLo がそれぞれ 8回
ラッチクロックLo ラッチクロックHi がそれぞれ 1回
なので、最低でも26クロックの動作時間が必要です、が、実際には関数呼び出しのオーバヘッドやif文、データのビット操作等でもっと時間がかかる(前回のプログラムの場合追加で17クロック程度)と思われます。
ハードウエア処理の場合(初期化等は除く)
SPDRレジスタへのデータセットをするだけで送信が開始されます。
送信は最速で1bitの送信に2クロックかかるので8bitで16クロック分
最後にラッチの操作で2クロック
よって20クロックで完了します。6クロックだけの差のようにみえますが、こちらはオーバーヘッド等の余分に必要な時間はないため実際にはソフトウエアよりももっと短時間でできると考えられます(実際には31クロック(約50%)の削減)。なによりコードサイズが大きくちがうはずです。
回路図
変更点はクロックとデータ線をUSCKとMOSIに移動させました。電源等は省略されています。以前利用したATtiny2313にはSPI機能が搭載されていないので手元にあったATmega88を利用しました。SPI機能を他のSPI接続のADコンバーター等と併用していても74HC595のラッチクロックがCSの代わりとして機能し、正しく個別に操作できます。
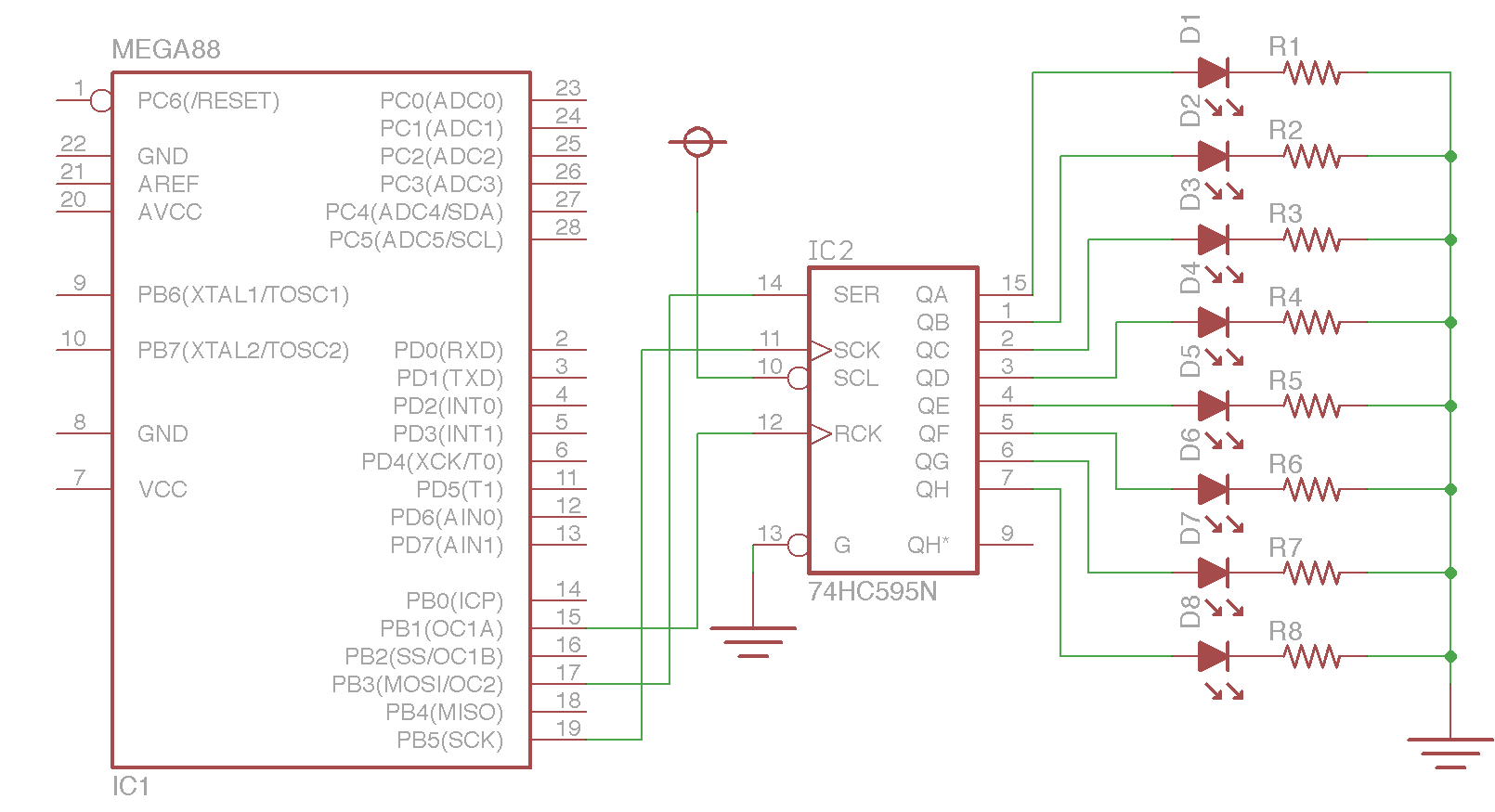
74HC595実験回路図(SPI利用)
AVRのプログラム
2010年5月15日訂正:なんと大変なことにSPCRレジスタの設定を間違えていました。
マスター動作に設定しないといけないのにスレーブになっていました。
自分で動作確認したのにいつの間にそうなってしまったのか…
#include <avr/io.h>
#include <util/delay.h>
#define SHIFT_PORT PORTB
#define SHIFT_RCK PB1
void delay_ms(uint16_t ms){
while(ms--){
_delay_ms(1);
}
}
void _shift_rck(){ //ラッチクロックを一つ送信
SHIFT_PORT &= ~(1<<SHIFT_RCK);
SHIFT_PORT |= (1<<SHIFT_RCK);
}
void shift_out(uint8_t data){
int8_t i;
SPDR = data; //データセットで送信開始
while(!(SPSR & (1<<SPIF))); //転送完了まで待機
_shift_rck(); //ラッチを更新
}
void init_spi(){
//SPIクロックは最速のfOSC/2
SPCR = 0b01010000;
SPSR = 0b00000001;
}
int main(){
uint16_t i;
uint8_t t;
DDRB = 0b00101111; //入出力設定(SSはSPIの動作時は出力にしておく)
init_spi(); //SPI初期設定
while(1){
//0から255までをカウントアップして出力
for(i=0;i<=0xff;i++){
shift_out(i);
delay_ms(30);
}
//バーを延ばしたり縮めたり
for(t=0;t<5;t++){
for(i=0;i<9;i++){
shift_out((0xff>>(8-(i%9))));
delay_ms(70);
}
for(i=0;i<9;i++){
shift_out((0xff>>(i%9)));
delay_ms(70);
}
}
//左右にスクロール
for(t=0;t<5;t++){
for(i=0;i<8;i++){
shift_out((1<<(i%8)));
delay_ms(70);
}
for(i=0;i<8;i++){
shift_out((0x80>>(i%8)));
delay_ms(70);
}
}
}
return 0;
}
どうですか?ソフトウエアの場合と比較してみてください。プログラムの行数では少しの削減に見えるかもしれません。ですが、前回のfor構文等を展開すると莫大な削減になっているとわかると思います。
動作実験
それでは実際に動作している映像を…と行きたいところですが、前回の映像との違いはありませんので、写真だけ載せます。

74HC595 with SPI
比較実験
コードサイズ
次のような延々とシフトレジスタにデータを送りつけるプログラムをIOポートを直接叩く方法とSPIで操作する方法のそれぞれの関数とともにコンパイルしたときのコードサイズを比較します。
uint8_t tmp;
while(1){
shift_out(tmp++);
}
結果、IOポートを叩く場合 188bytes、SPIを利用する場合 148bytes となり、40bytesの削減になりました。
空のプログラムをコンパイルした時のコードサイズが80bytesだったので、シフトレジスタ操作部分だけを計算すると、108bytesから68bytesと37%の削減になりました。
動作速度
先程のプログラムをそれぞれ実行し、74HC595のRCK端子に出力されるパルスの周波数、パルスの間隔を測定することにより動作速度を検証します。
今回はRCKを周波数カウンタに入力し周波数を調べました。

IOポートを叩いた時のRCK周波数(334kHz)

SPIを用いた時のRCK周波数(653kHz)
結果、I/Oポートを叩いた場合334kHz、SPIを使った場合653kHzと、ほぼ試算通り約49%の削減となりました。